
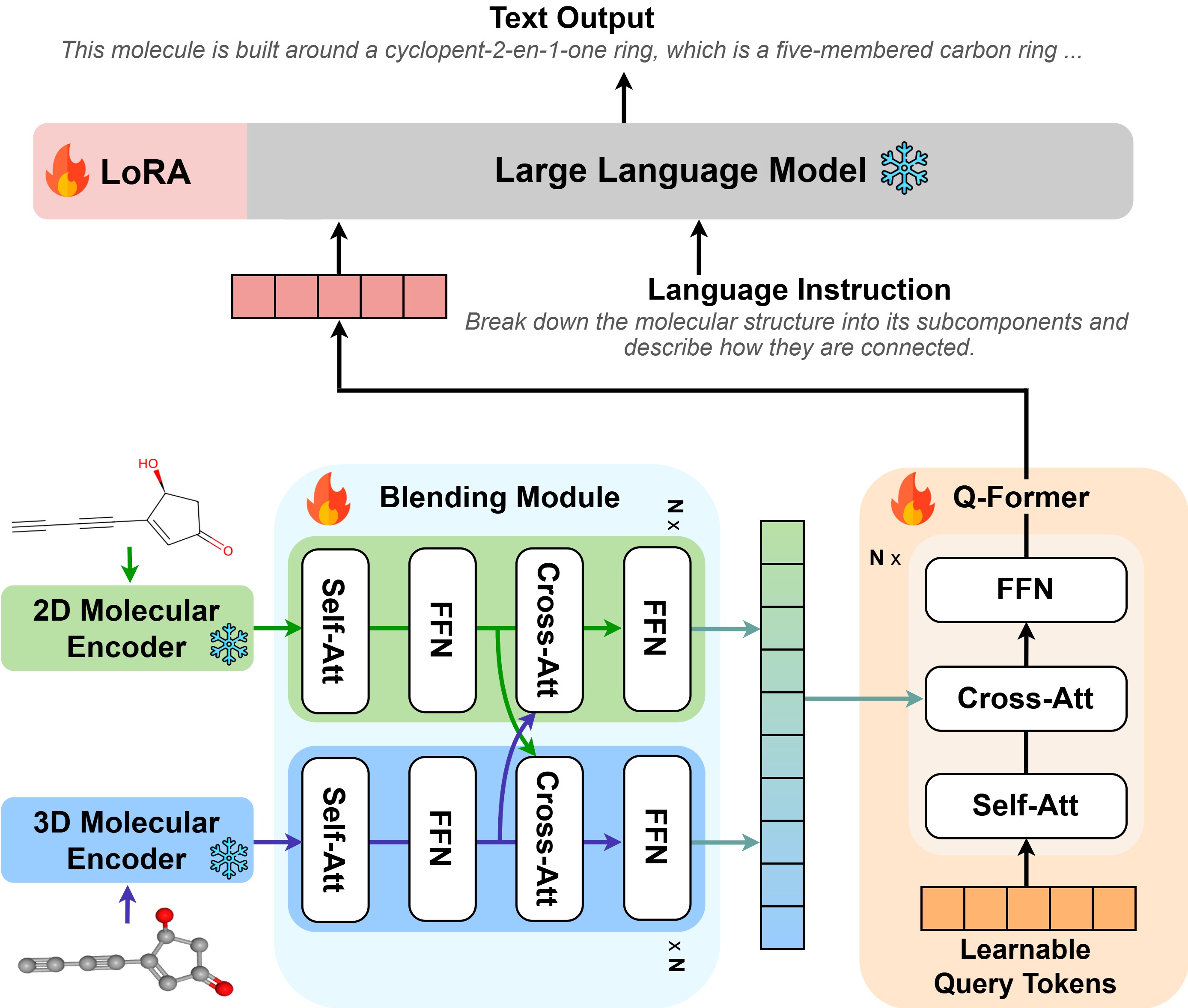
We propose Mol-LLaMA, a large molecular language model that grasps the general knowledge centered on molecules via multi-modal instruction tuning. To this end, we design key data types that encompass the fundamental features of molecules, incorporating essential knowledge from molecular structures. In addition, to improve understanding of molecular features, we introduce a module that integrates complementary information from different molecular encoders, leveraging the distinct advantages of different molecular representations.


By leveraging PubChem dataset and GPT-4o, we construct an instruction dataset that entails the core knowledge of molecules encompassing structural, chemical, and chemical features, establishing 77k in detailed structrual descriptions, 147k in structure-to-feature relationship explanations, and 60k in comprehensive conversations.




Mol-LLaMA is built on both 2D and 3D molecular encoders to capture the complementary information from different molecular representations. We propose a blending module that integrates the information from different molecular encoders based on the cross-attention, leveraging the distinct advantages of different molecular representations.
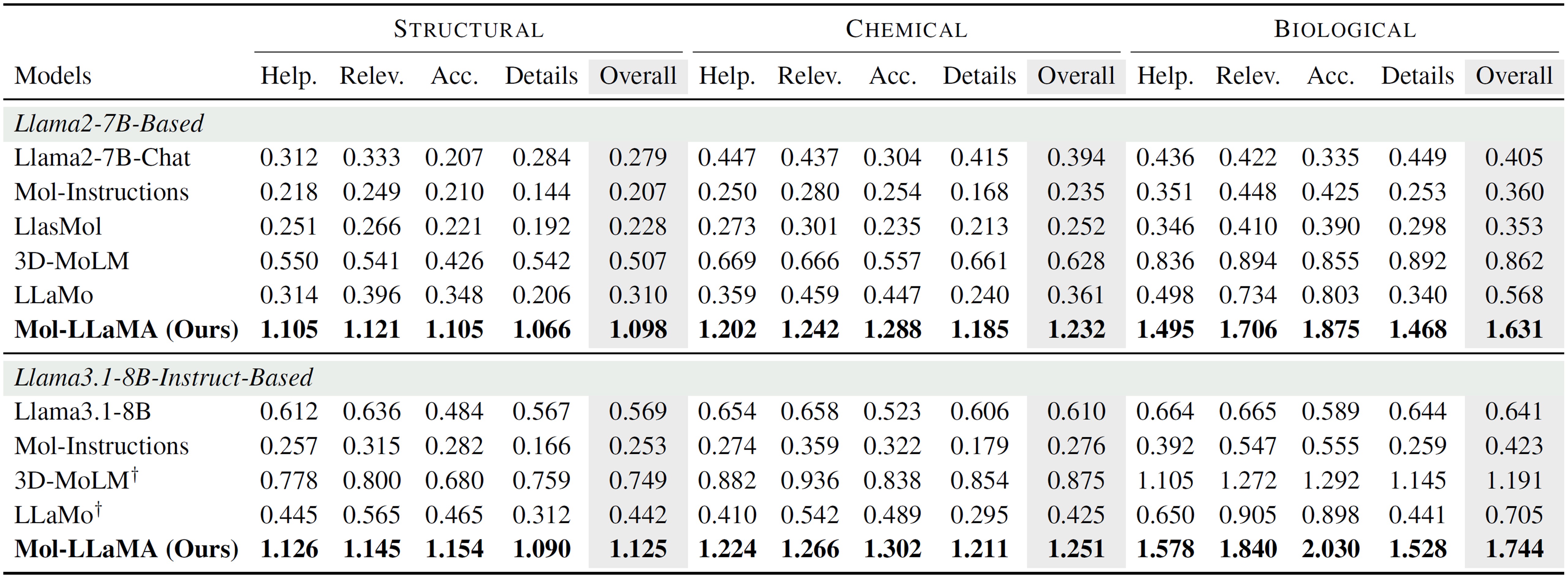
We evaluate Mol-LLaMA on 100 unseen molecules by asking general questions about the structural, chemical, and biological features of a given molecule. Relative scores of Mol-LLaMA compared to GPT-4o are beyond 1 for all criteria, indicating that it is superior to GPT-4o in the understanding of general features of molecules.
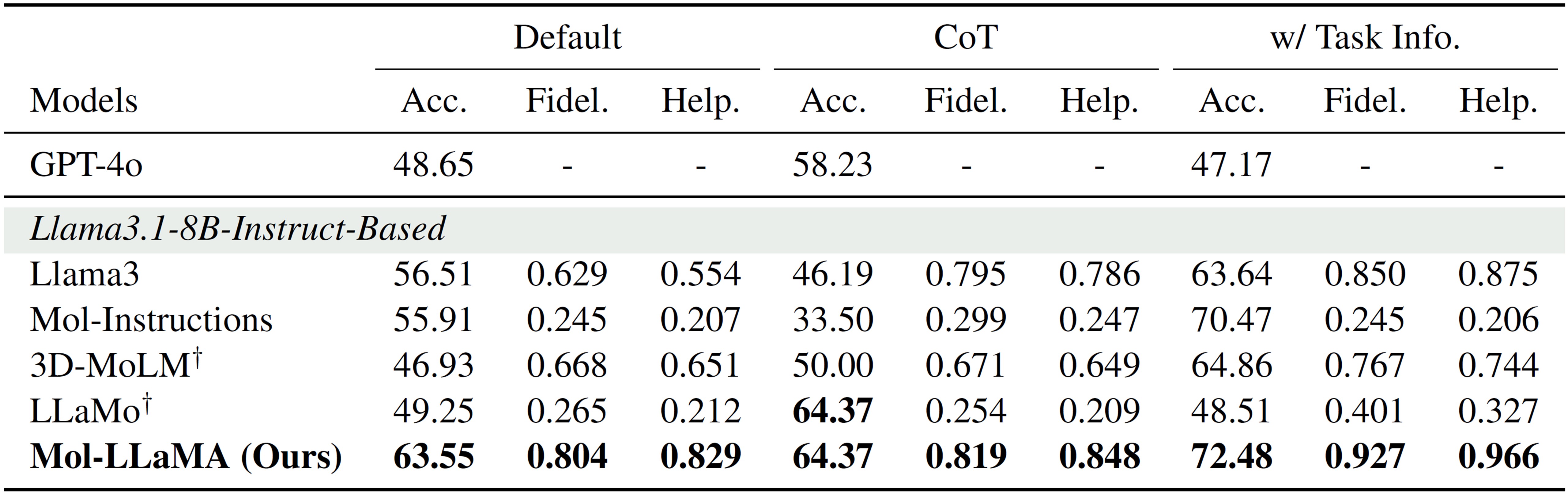
We evaluate Mol-LLaMA on PAMPA task where the task is to classify whether the given molecule has a high permeability or a low-to-moderate permeability to the artificial membrane. Mol-LLaMA achieves high accuracy outperforming GPT-4o, while showing high fidelity and helpfulness scores, demonstrating that it is able to accurately predict the molecular property with helpful explanations.

Mol-LLaMA provides the prediction of the molecular property with the explanation of the molecular features that contribute to the prediction, which can be helpful for the users to understand the prediction and the underlying reasons.
@inproceedings{kim2025molllama,
title={Mol-LLaMA: Towards General Understanding of Molecules in Large Molecular Language Model},
author={Dongki Kim and Wonbin Lee and Sung Ju Hwang},
booktitle={arXiv:2502.13449},
year={2025}
}